
分布式存储之GlusterFS
浏览量:2317
一、理论基础
1.1、分布式文件系统的出现
计算机通过文件系统管理、存储数据,而现在数据信息爆炸的时代中人们可以获取的数据成指数倍的增长,单纯通过增加硬盘个数来扩展计算机文件系统的存储容量的方式,已经不能满足目前的需求。
分布式文件系统可以有效解决数据的存储和管理难题,将固定于某个地点的某个文件系统,扩展到任意多个地点/多个文件系统,众多的节点组成一个文件系统网络。每个节点可以分布在不同的地点,通过网络进行节点间的通信和数据传输。人们在使用分布式文件系统时,无需关心数据是存储在哪个节点上、或者是从哪个节点从获取的,只需要像使用本地文件系统一样管理和存储文件系统中的数据。
1.2、典型代表NFS
NFS(Network File System)即网络文件系统,它允许网络中的计算机之间通过TCP/IP网络共享资源。在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样。
NFS的优点如下:
1.节约使用的磁盘空间
客户端经常使用的数据可以集中存放在一台机器上,并使用NFS发布,那么网络内部所有计算机可以通过网络访问,不必单独存储.
2.节约硬件资源
NFS还可以共享软驱,CDROM和ZIP等的存储设备,减少整个网络上的可移动设备的数量.
3.用户主目录设定
对于特殊用户,如管理员等,为了管理的需要,可能会经常登录到网络中所有的计算机,若每个客户端,均保存这个用户的主目录很繁琐,而且不能保证数据的一致性.实际上,经过NFS服务的设定,然后在客户端指定这个用户的主目录位置,并自动挂载,就可以在任何计算机上使用用户主目录的文件。
1.3、面临的问题
a、存储空间不足,需要更大容量的存储。
b、直接用NFS挂载存储,有一定风险,存在单点故障。
c、某些场景不能满足要求,大量的访问磁盘IO是瓶颈。
1.4 GlusterFS概述
GlusterFS是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS借助TCP/IP或InfiniBand RDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
GlusterFS支持运行在任何标准IP网络上标准应用程序的标准客户端,用户可以在全局统一的命名空间中使用NFS/CIFS等标准协议来访问应用数据。GlusterFS使得用户可摆脱原有的独立、高成本的封闭存储系统,能够利用普通廉价的存储设备来部署可集中管理、横向扩展、虚拟化的存储池,存储容量可扩展至TB/PB级。
GlusterFS 旨在成为一个通用的、 PB 级存储的、可线性扩展的分布式文件系统,提供统一的全局命名空间,并支持 NFS 、 CIFS 、 HTTP 等通用的网络访问协议。
GlusterFS 的大部分功能都是使用 Translator 机制来实现的,这借鉴了 GNU/Hurd 的设计思想,将功能点设计成一个个的 translator 。每一个 translator 被编译成了共享库文件( .so 文件),并定义了统一的接口,这样通过串行组合很多的 translator 就可以很灵活地实现复杂的功能。在GlusterFS 中使用的 translator 主要有:
1) Cluster :各种集群模式,目前有 AFR ( Automatic File Replication )、 DHT (Distributed Hash Table )、 Stripe ;
2) Features :特色功能,有 locks 、 read-only 、 trash 等;
3) Performance :跟性能相关的功能,有 io-cache 、 io-threads 、 quick-read 、 read-ahead 、 write-behind 等;
4) Protocol : Gluster Native Protocol 通信协议的客户端和服务器端实现,有 client 、server 等;
5) Storage :跟本地文件系统直接交互的 POSIX 接口实现;
6) NFS :将 GlusterFS 以 NFS 服务器的形式提供服务的功能;
7) System :目前有 posix-acl ,提供访问控制功能;
8) Mount : FUSE 接口实现;
9) Mgmt :弹性卷管理器;
10) Encryption :加密功能;
11) Debug :系统调试相关的功能实现;
目前glusterfs 已被redhat收购,它的官方网站是:http://www.gluster.org/
1.5 GlusterFS外部架构
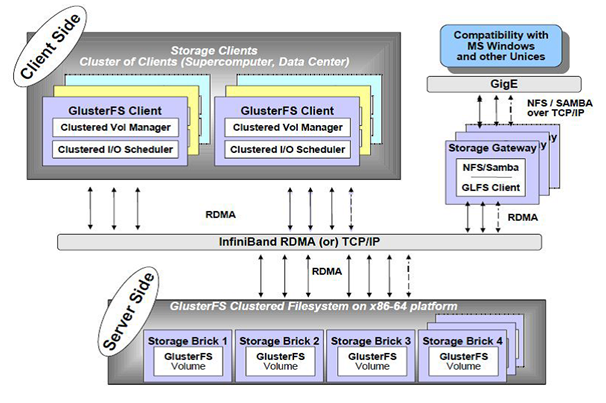
lusterFS总体架构与组成部分如图所示,它主要由存储服务器(BrickServer)、客户端以及NFS/Samba 存储网关组成。不难发现,GlusterFS 架构中没有元数据服务器组件,这是其最大的设计这点,对于提升整个系统的性能、可靠性和稳定性都有着决定性的意义。
GlusterFS 支持TCP/IP 和InfiniBandRDMA 高速网络互联,客户端可通过原生Glusterfs 协议访问数据,其他没有运行GlusterFS客户端的终端可通过NFS/CIFS 标准协议通过存储网关访问数据。
1.6、GlusterFS内部架构
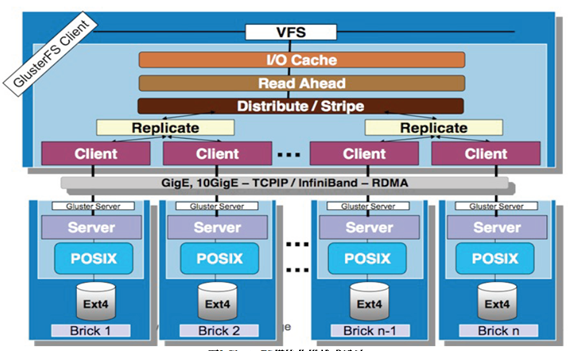
GlusterFS是模块化堆栈式的架构设计,如上图所示。模块称为Translator,是GlusterFS提供的一种强大机制,借助这种良好定义的接口可以高效简便地扩展文件系统的功能。
1.服务端与客户端模块接口是兼容的,同一个translator可同时在两边加载。
2.GlusterFS中所有的功能都是通过translator实现,如Cluster, Storage,Performance, Protocol, Features等。
3.重点是GlusterFSClient端。
1.7、GlusterFS数据访问流程
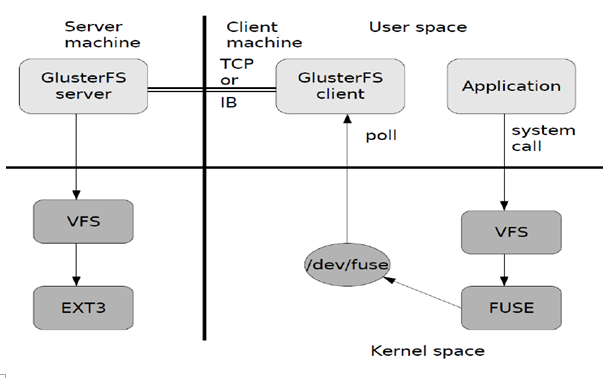
上图是GlusterFS数据访问的一个概要图:
1.首先是在客户端,用户通过glusterfs的mount point 来读写数据。
2.用户的这个操作被递交给本地linux系统的VFS来处理。
3.VFS将数据递交给FUSE内核文件系统,在启动glusterfs客户端以前,需要向系统注册一个实际的文件系统FUSE,如上图所示,该文件系统与ext3在同一个层次上面,ext3是对实际的磁片进行处理,而fuse文件系统则是将数据通过/dev/fuse这个设备文件递交给了glusterfs client端。所以,我们可以将fuse文件系统理解为一个代理。
4.数据被fuse递交给Glusterfs client 后,client对数据进行一些指定的处理(所谓的指定,是按照client配置文件来进行的一系列处理)
5.在glusterfsclient的处理末端,通过网路将数据递交给Glusterfs Server,并且将数据写入到服务器所控制的存储设备上
1.8 技术特点
GlusterFS在技术实现上与传统存储系统或现有其他分布式文件系统有显著不同之处,主要体现在如下几个方面。
完全软件实现(SoftwareOnly)
GlusterFS认为存储是软件问题,不能够把用户局限于使用特定的供应商或硬件配置来解决。GlusterFS采用开放式设计,广泛支持工业标准的存储、网络和计算机设备,而非与定制化的专用硬件设备捆绑。对于商业客户,GlusterFS可以以虚拟装置的形式交付,也可以与虚拟机容器打包,或者是公有云中部署的映像。开源社区中,GlusterFS被大量部署在基于廉价闲置硬件的各种操作系统上,构成集中统一的虚拟存储资源池。简言之,GlusterFS是开放的全软件实现,完全独立于硬件和操作系统。
完整的存储操作系统栈(CompleteStorage Operating System Stack)
GlusterFS不仅提供了一个分布式文件系统,而且还提供了许多其他重要的分布式功能,比如分布式内存管理、I/O调度、软RAID和自我修复等。GlusterFS汲取了微内核架构的经验教训,借鉴了GNU/Hurd操作系统的设计思想,在用户空间实现了完整的存储操作系统栈。
用户空间实现(User Space)
与传统的文件系统不同,GlusterFS在用户空间实现,这使得其安装和升级特别简便。另外,这也极大降低了普通用户基于源码修改GlusterFS的门槛,仅仅需要通用的C程序设计技能,而不需要特别的内核编程经验。
模块化堆栈式架构(ModularStackable Architecture)
GlusterFS采用模块化、堆栈式的架构,可通过灵活的配置支持高度定制化的应用环境,比如大文件存储、海量小文件存储、云存储、多传输协议应用等。每个功能以模块形式实现,然后以积木方式进行简单的组合,即可实现复杂的功能。比如,Replicate模块可实现RAID1,Stripe模块可实现RAID0,通过两者的组合可实现RAID10和RAID01,同时获得高性能和高可性。
原始数据格式存储(DataStored in Native Formats)
GlusterFS无元数据服务设计(NoMetadata with the Elastic Hash Algorithm)以原始数据格式(如EXT3、EXT4、XFS、ZFS)储存数据,并实现多种数据自动修复机制。因此,系统极具弹性,即使离线情形下文件也可以通过其他标准工具进行访问。如果用户需要从GlusterFS中迁移数据,不需要作任何修改仍然可以完全使用这些数据。
对Scale-Out存储系统而言,最大的挑战之一就是记录数据逻辑与物理位置的映像关系,即数据元数据,可能还包括诸如属性和访问权限等信息。传统分布式存储系统使用集中式或分布式元数据服务来维护元数据,集中式元数据服务会导致单点故障和性能瓶颈问题,而分布式元数据服务存在性能负载和元数据同步一致性问题。特别是对于海量小文件的应用,元数据问题是个非常大的挑战。
GlusterFS独特地采用无元数据服务的设计,取而代之使用算法来定位文件,元数据和数据没有分离而是一起存储。集群中的所有存储系统服务器都可以智能地对文件数据分片进行定位,仅仅根据文件名和路径并运用算法即可,而不需要查询索引或者其他服务器。这使得数据访问完全并行化,从而实现真正的线性性能扩展。无元数据服务器极大提高了GlusterFS的性能、可靠性和稳定性。
一些设计与讨论
无元数据服务器vs 元数据服务器
无元数据服务器设计的好处是没有单点故障和性能瓶颈问题,可提高系统扩展性、性能、可靠性和稳定性。对于海量小文件应用,这种设计能够有效解决元数据的难点问题。它的负面影响是,数据一致问题更加复杂,文件目录遍历操作效率低下,缺乏全局监控管理功能。同时也导致客户端承担了更多的职能,比如文件定位、名字空间缓存、逻辑卷视图维护等等,这些都增加了客户端的负载,占用相当的CPU 和内存。
用户空间vs内核空间
用户空间实现起来相对要简单许多,对开发者技能要求较低,运行相对安全。用户空间效率低,数据需要多次与内核空间交换,另外GlusterFS 借助FUSE 来实现标准文件系统接口,性能上又有所损耗。内核空间实现可以获得很高的数据吞吐量,缺点是实现和调试非常困难,程序出错经常会导致系统崩溃,安全性低。纵向扩展上,内核空间要优于用户空间,GlusterFS 有横向扩展能力来弥补。
堆栈式vs 非堆栈式
这有点像操作系统的微内核设计与单一内核设计之争。GlusterFS 堆栈式设计思想源自GNU/Hurd 微内核操作系统,具有很强的系统扩展能力,系统设计实现复杂性降低很多,基本功能模块的堆栈式组合就可以实现强大的功能。查看GlusterFS卷配置文件我们可以发现,translator 功能树通常深达10层以上,一层一层进行调用,效率可见一斑。非堆栈式设计可看成类似Linux 的单一内核设计,系统调用通过中断实现,非常高效。后者的问题是系统核心臃肿,实现和扩展复杂,出现问题调试困难。
原始存储格式vs 私有存储格式
GlusterFS使用原始格式存储文件或数据分片,可以直接使用各种标准的工具进行访问,数据互操作性好,迁移和数据管理非常方便。然而,数据安全成了问题,因为数据是以平凡的方式保存的,接触数据的人可以直接复制和查看。这对很多应用显然是不能接受的,比如云存储系统,用户特别关心数据安全,这也是影响公有云存储发展的一个重要原因。私有存储格式可以保证数据的安全性,即使泄露也是不可知的。GlusterFS 要实现自己的私有格式,在设计实现和数据管理上相对复杂一些,也会对性能产生一定影响。
大文件vs 小文件
GlusterFS 适合大文件还是小文件存储?弹性哈希算法和Stripe 数据分布策略,移除了元数据依赖,优化了数据分布,提高数据访问并行性,能够大幅提高大文件存储的性能。对于小文件,无元数据服务设计解决了元数据的问题。但GlusterFS 并没有在I/O 方面作优化,在存储服务器底层文件系统上仍然是大量小文件,本地文件系统元数据访问是一个瓶颈,数据分布和并行性也无法充分发挥作用。因此,GlusterFS 适合存储大文件,小文件性能较差,还存在很大优化空间。
可用性vs 存储利用率
GlusterFS使用复制技术来提供数据高可用性,复制数量没有限制,自动修复功能基于复制来实现。可用性与存储利用率是一个矛盾体,可用性高存储利用率就低,反之亦然。采用复制技术,存储利用率为1/复制数,镜像是50%,三路复制则只有33%。其实,可以有方法来同时提高可用性和存储利用率,比如RAID5的利用率是(n-1)/n,RAID6是(n-2)/n,而纠删码技术可以提供更高的存储利用率。但是,鱼和熊掌不可得兼,它们都会对性能产生较大影响。
术语表:
Xlator=translator:glusterfs 模块的代名词 Brick :存储目录是Glusterfs 的基本存储单元,由可信存储池中服务器上对外 输出的目录表示。存储目录的格式由服务器和目录的绝对路径构成,具体如下: SERVER:EXPORT.例如:myhostname:/exports/myexportdir/ Volume :卷是存储目录的逻辑组合。大部分gluster 管理操作是在卷上进行的。 Metadata:元数据关于数据的数据,用于描述文件、目录等的相关信息。 FUSE=Filesystem inUserspace: 是一个内核模块,允许用户创建自己的文件系 统无需修改内核代码。 Glusterd : Glusterfs 后台进程,运行在所有Glusterfs 节点上。 DistributeVolume: 分布式卷 ReplicateVolume: 副本卷 StripeVolume: 条带卷 DistributeReplicate Volume: 分布式副本卷 DHT=Distribute HashTable AFR=Automatic FileReplication SAN = Storage AreaNetwork: 存储区域网络是一种高速网络或子网络,提供在计算机与存储之间的数据传输。 NAS = Network-attachedstorage:网络附属存储是一种将分布、独立的数据整合为大型、集中化管理的数据中心,以便于对不同主机和应用服务器进行访问的技术。 RPC =Remote ProcedureCall: 远程过程调用 XDR =eXtern DataRepresentation: RPC 传递数据的格式 CLI=Command LineInterface 控制台 argp=Argument Parser UUID=University UnqiueIdentifier SVC =service CLNT =client MGMT=management cbks = Call Backs ctx = context lk = lock attr = attribute txn = transaction rb = replace brick worm = write once , readmany
1.9、 应用场景
理论和实践上分析,GlusterFS目前主要适用大文件存储场景,对于小文件尤其是海量小文件,存储效率和访问性能都表现不佳。
海量小文件LOSF问题是工业界和学术界公认的难题,GlusterFS作为通用的分布式文件系统,并没有对小文件作额外的优化措施,性能不好也是可以理解的。
Media
−文档、图片、音频、视频
•Shared storage
−云存储、虚拟化存储、HPC(高性能计算)
•Big data
−日志文件、RFID(射频识别)数据
二、GlusterFS实战演练
2.1、安装前准备
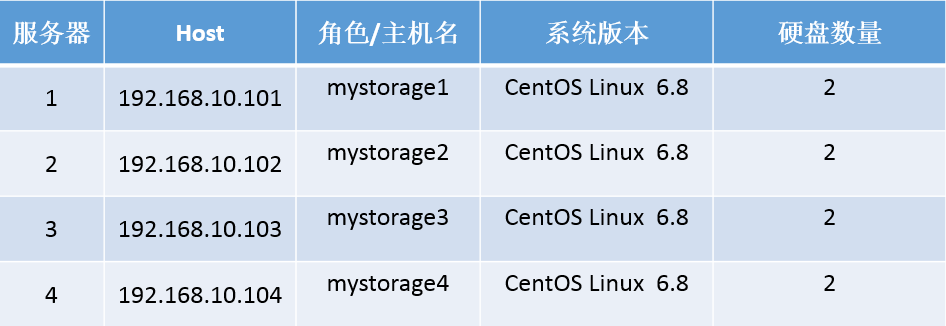
注意:关闭防火墙和selinux
2.2 GlusterFS安装
2.2.1 修改主机名
需要修改两处:一处是/etc/sysconfig/network,另一处是/etc/hosts,只修改任一处会导致系统启动异常。
/etc/sysconfig/network
用vi编辑器,里面有一行 HOSTNAME=localhost.localdomain (如果是默认的话),修改 localhost.localdomain 为你的主机名。
/etc/hosts
打开该文件,会有一行 127.0.0.1 localhost.localdomain localhost 。其中 127.0.0.1 是本地环路地址, localhost.localdomain 是主机名(hostname),也就是你待修改的。localhost 是主机名的别名(alias)。将第二项修改为你的主机名,第三项可选。
将上面两个文件修改完后,并不能立刻生效。如果要立刻生效的话,可以用 hostname your-hostname 作临时修改,它只是临时地修改主机名,系统重启后会恢复原样的。但修改上面两个文件是永久的,重启系统会得到新的主机名。
最后,重启后查看主机名 uname -n 。
2.2.2 添加hosts文件实现主机互信
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.101 mystorage1 192.168.10.102 mystorage2 192.168.10.103 mystorage3 192.168.10.104 mystorage4
2.2.3 关闭selinux及防火墙
关闭selinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux 或者 sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
也可以用vi 直接编辑修改
关闭防火墙
关闭命令: service iptables stop
永久关闭防火墙:chkconfig iptables off
两个命令同时运行,运行完成后查看防火墙关闭状态
service iptables status
2.2.4 安装epel源
注意:GlusterFS源有部分依赖epel源
yum –y install epel-release
2.2.5 安装:
[root@linux-node1 ~]# yum install centos-release-gluster -y [root@linux-node1 ~]# yum install glusterfs-server -y [root@linux-node1 ~]# rpm -qa glusterfs* glusterfs-3.10.2-1.el6.x86_64 glusterfs-fuse-3.10.2-1.el6.x86_64 glusterfs-libs-3.10.2-1.el6.x86_64 glusterfs-client-xlators-3.10.2-1.el6.x86_64 glusterfs-api-3.10.2-1.el6.x86_64 glusterfs-server-3.10.2-1.el6.x86_64 glusterfs-cli-3.10.2-1.el6.x86_64
2.3 配置glusterfs
2.3.1 查看gluster版本
glusterfs -V
2.3.2 启动/停止服务
service glusterd start service glusterd stop 添加开机启动 chkconfig glusterd on
2.3.3 存储主机加入信任存储池
gluster peer probe mystorage2 gluster peer probe mystorage3 gluster peer probe mystorage4
2.3.4 查看状态
gluster peer status
2.3.5 配置前准备工作
安装xfs支持包
yum -y install xfsprogs
fdisk –l 查看磁盘块设备 ,查看类似的信息
[root@mystorage1 ~]# fdisk -l Disk /dev/sda: 128.8 GB, 128849018880 bytes 255 heads, 63 sectors/track, 15665 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x000bf498 Device Boot Start End Blocks Id System /dev/sda1 * 1 26 204800 83 Linux Partition 1 does not end on cylinder boundary. /dev/sda2 26 15568 124836864 83 Linux /dev/sda3 15568 15666 786432 82 Linux swap / Solaris Disk /dev/sdb: 53.7 GB, 53687091200 bytes 255 heads, 63 sectors/track, 6527 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00000000 Disk /dev/sdc: 53.7 GB, 53687091200 bytes 255 heads, 63 sectors/track, 6527 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00000000
执行:
fdisk /dev/vdb n p 1 回车 w
再次fdisk -l查看
[root@mystorage1 ~]# fdisk -l Disk /dev/sda: 128.8 GB, 128849018880 bytes 255 heads, 63 sectors/track, 15665 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x000bf498 Device Boot Start End Blocks Id System /dev/sda1 * 1 26 204800 83 Linux Partition 1 does not end on cylinder boundary. /dev/sda2 26 15568 124836864 83 Linux /dev/sda3 15568 15666 786432 82 Linux swap / Solaris Disk /dev/sdb: 53.7 GB, 53687091200 bytes 255 heads, 63 sectors/track, 6527 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x6e26883d Device Boot Start End Blocks Id System /dev/sdb1 1 6527 52428096 83 Linux Disk /dev/sdc: 53.7 GB, 53687091200 bytes 255 heads, 63 sectors/track, 6527 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0xc7db7886 Device Boot Start End Blocks Id System /dev/sdc1 1 6527 52428096 83 Linux
在其他机器上执行同样的操作,依次给磁盘进行分区
接下来对磁盘进行格式化,在每台机器执行: mkdir -p /storage/brick1 /storage/brick2
[root@mystorage1 ~]# mkfs.xfs -f /dev/sdb1 [root@mystorage1 ~]# mkfs.xfs -f /dev/sdc1
在 /etc/fstab 文件中加入 两行
/dev/sdb1 /storage/brick1 xfs defaults 0 0 /dev/sdc1 /storage/brick2 xfs defaults 0 0
方法二、
echo "/dev/sdb1 /storage/brick1 xfs defaults 0 0" >> /etc/fstab echo "/dev/sdc1 /storage/brick2 xfs defaults 0 0" >> /etc/fstab mount -a
2.3.6 创建volume及其他操作
Distributed:分布式卷,文件通过hash算法随机的分布到由bricks组成的卷上。
Replicated: 复制式卷,类似raid1,replica数必须等于volume中brick所包含的存储服务器数,可用性高。
Striped : 条带式卷,类似与raid0,stripe数必须等于volume中brick所包含的存储服务器数,文件被分成数据块,以Round Robin的方式存储在bricks中,并发粒度是数据块,大文件性能好。
Distributed Striped:分布式的条带卷,volume中brick所包含的存储服务器数必须是stripe的倍数(>=2倍),兼顾分布式和条带式的功能。
Distributed Replicated:分布式的复制卷,volume中brick所包含的存储服务器数必须是 replica 的倍数(>=2倍),兼顾分布式和复制式的功能。
分布式卷
#创建分布式卷
[root@mystorage1 ~]# gluster volume create gv1 mystorage1:/storage/brick1 mystorage2:/storage/brick1 force volume create: gv1: success: please start the volume to access data
#启动分布式卷
[root@mystorage1 ~]# gluster volume start gv1 volume start: gv1: success
#查看信息
[root@mystorage1 ~]# gluster volume info Volume Name: gv1 Type: Distribute Volume ID: c4d4a5f2-1ed4-4ddf-a314-9dcbfb67894b Status: Started Number of Bricks: 2 Transport-type: tcp Bricks: Brick1: mystorage1:/storage/brick1 Brick2: mystorage2:/storage/brick1 Options Reconfigured: performance.readdir-ahead: on
#挂载卷到目录
[root@mystorage1 ~]# mount -t glusterfs 127.0.0.1:/gv1 /mnt [root@mystorage1 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda2 118G 1.6G 110G 2% / tmpfs 491M 0 491M 0% /dev/shm /dev/sda1 190M 36M 145M 20% /boot /dev/sdb1 50G 33M 50G 1% /storage/brick1 /dev/sdc1 50G 33M 50G 1% /storage/brick2 127.0.0.1:/gv1 100G 65M 100G 1% /mnt
#主机2执行上面挂载并查看挂载情况
[root@mystorage2 ~]# mount -t glusterfs 127.0.0.1:/gv1 /mnt [root@mystorage2 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda2 118G 1.5G 110G 2% / tmpfs 491M 0 491M 0% /dev/shm /dev/sda1 190M 36M 145M 20% /boot /dev/sdb1 50G 33M 50G 1% /storage/brick1 /dev/sdc1 50G 33M 50G 1% /storage/brick2 127.0.0.1:/gv1 100G 65M 100G 1% /mnt
#主机mystorage1创建文件测试
[root@mystorage1 mnt]# touch aa bb cc dd ee ff [root@mystorage1 mnt]# ls aa bb cc dd ee ff
#主机mystorage3用nfs方式挂载
[root@mystorage1 mnt]# ls aa bb cc dd ee ff
分布式复制卷
#创建分布式复制卷
[root@mystorage1 ~]# gluster volume create gv2 replica 2 mystorage1:/storage/brick2 mystorage2:/storage/brick2 force volume create: gv2: success: please start the volume to access data
#查看卷信息
[root@mystorage1 ~]# gluster volume info Volume Name: gv1 Type: Distribute Volume ID: c4d4a5f2-1ed4-4ddf-a314-9dcbfb67894b Status: Started Number of Bricks: 2 Transport-type: tcp Bricks: Brick1: mystorage1:/storage/brick1 Brick2: mystorage2:/storage/brick1 Options Reconfigured: performance.readdir-ahead: on Volume Name: gv2 Type: Replicate Volume ID: ee6aee88-a837-43dd-9335-148e09086248 Status: Created Number of Bricks: 1 x 2 = 2 Transport-type: tcp Bricks: Brick1: mystorage1:/storage/brick2 Brick2: mystorage2:/storage/brick2 Options Reconfigured: performance.readdir-ahead: on
分布式条带卷
#创建分布式带条卷
[root@mystorage1 ~]# gluster volume create gv3 stripe 2 mystorage3:/storage/brick1 mystorage4:/storage/brick1 force volume create: gv3: success: please start the volume to access data
#查看卷信息
[root@mystorage1 ~]# gluster volume info Volume Name: gv1 Type: Distribute Volume ID: c4d4a5f2-1ed4-4ddf-a314-9dcbfb67894b Status: Started Number of Bricks: 2 Transport-type: tcp Bricks: Brick1: mystorage1:/storage/brick1 Brick2: mystorage2:/storage/brick1 Options Reconfigured: performance.readdir-ahead: on Volume Name: gv2 Type: Replicate Volume ID: ee6aee88-a837-43dd-9335-148e09086248 Status: Created Number of Bricks: 1 x 2 = 2 Transport-type: tcp Bricks: Brick1: mystorage1:/storage/brick2 Brick2: mystorage2:/storage/brick2 Options Reconfigured: performance.readdir-ahead: on Volume Name: gv3 Type: Stripe Volume ID: e1abd01d-886a-46ac-9931-632014d07c4b Status: Created Number of Bricks: 1 x 2 = 2 Transport-type: tcp Bricks: Brick1: mystorage3:/storage/brick1 Brick2: mystorage4:/storage/brick1 Options Reconfigured: performance.readdir-ahead: on
#启动并挂载
[root@mystorage1 ~]# gluster volume start gv2 volume start: gv2: success [root@mystorage1 ~]# gluster volume start gv3 volume start: gv3: success [root@mystorage1 ~]# mkdir -p /gv1 /gv2 /gv3 [root@mystorage1 ~]# umount /mnt/ [root@mystorage1 ~]# mount -t glusterfs 127.0.0.1:gv1 /gv1 [root@mystorage1 ~]# mount -t glusterfs 127.0.0.1:gv2 /gv2 [root@mystorage1 ~]# mount -t glusterfs 127.0.0.1:gv3 /gv3 [root@mystorage1 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda2 118G 1.6G 110G 2% / tmpfs 491M 0 491M 0% /dev/shm /dev/sda1 190M 36M 145M 20% /boot /dev/sdb1 50G 33M 50G 1% /storage/brick1 /dev/sdc1 50G 33M 50G 1% /storage/brick2 127.0.0.1:gv1 100G 65M 100G 1% /gv1 127.0.0.1:gv2 50G 33M 50G 1% /gv2 127.0.0.1:gv3 100G 65M 100G 1% /gv3
#测试并查看
[root@mystorage1 brick2]# ls a b c d e f [root@mystorage1 brick2]# cd /gv3/ [root@mystorage1 gv3]# ls [root@mystorage1 gv3]# touch e f g h i j k l m n [root@mystorage1 gv3]# dd if=/dev/zero bs=1024 count=10000 of=/gv3/10M.file 10000+0 records in 10000+0 records out 10240000 bytes (10 MB) copied, 4.76461 s, 2.1 MB/s [root@mystorage3 ~]# cd /storage/brick1/ [root@mystorage3 brick1]# ls -lh total 5.0M -rw-r--r-- 2 root root 4.9M Jun 23 02:51 10M.file -rw-r--r-- 2 root root 0 Jun 23 2017 e -rw-r--r-- 2 root root 0 Jun 23 2017 f -rw-r--r-- 2 root root 0 Jun 23 2017 g -rw-r--r-- 2 root root 0 Jun 23 2017 h -rw-r--r-- 2 root root 0 Jun 23 2017 i -rw-r--r-- 2 root root 0 Jun 23 2017 j -rw-r--r-- 2 root root 0 Jun 23 2017 k -rw-r--r-- 2 root root 0 Jun 23 2017 l -rw-r--r-- 2 root root 0 Jun 23 2017 m -rw-r--r-- 2 root root 0 Jun 23 2017 n
注意:如果以后要添加服务器,扩容卷可以使用add-brick命令
[root@mystorage1 gv3]# gluster volume add-brick gv2 replica 2 mystorage3:/storage/brick2 mystorage4:/storage/brick2 force volume add-brick: success [root@mystorage1 gv3]# gluster volume info gv2 Volume Name: gv2 Type: Distributed-Replicate Volume ID: ee6aee88-a837-43dd-9335-148e09086248 Status: Started Number of Bricks: 2 x 2 = 4 Transport-type: tcp Bricks: Brick1: mystorage1:/storage/brick2 Brick2: mystorage2:/storage/brick2 Brick3: mystorage3:/storage/brick2 Brick4: mystorage4:/storage/brick2 Options Reconfigured: performance.readdir-ahead: on [root@mystorage1 gv3]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda2 118G 1.6G 110G 2% / tmpfs 491M 0 491M 0% /dev/shm /dev/sda1 190M 36M 145M 20% /boot /dev/sdb1 50G 33M 50G 1% /storage/brick1 /dev/sdc1 50G 33M 50G 1% /storage/brick2 127.0.0.1:gv1 100G 65M 100G 1% /gv1 127.0.0.1:gv2 50G 33M 50G 1% /gv2 127.0.0.1:gv3 100G 75M 100G 1% /gv3
注意:当你给分布式复制卷和分布式条带卷中增加bricks时,你增加的bricks的数目必须是复制或者条带数目的倍数,例如:你给一个分布式复制卷的replica为2,你在增加bricks的时候数量必须为2、4、6、8等。
扩容后进行测试,发现文件都分布,扩容前的卷中
[root@mystorage1 gv2]# ls a b c d e f [root@mystorage1 gv2]# touch 1 2 3 4 5 [root@mystorage1 brick1]# cd /storage/brick2/ [root@mystorage1 brick2]# ls 1 2 3 4 5 a b c d e f
磁盘存储的平衡
注意:平衡布局是很有必要的,因为布局结构是静态的,当新的bricks加入现有卷,新创建的文件会分布到旧的bricks中,所以需要平衡布局结构,使新加入 的bricks生效。布局平衡只是使新布局生效,并不会在新的布局移动老的数据,如果你想在新布局生效后,重新平衡卷中的数据,还需要对卷中的数据进行平衡。
执行命令:
[root@mystorage1 brick2]# gluster volume rebalance gv2 start volume rebalance: gv2: success: Rebalance on gv2 has been started successfully. Use rebalance status command to check status of the rebalance process. ID: 0c0e3f57-07c1-45b5-9e28-83378dd7ada7 [root@mystorage1 brick2]# gluster volume rebalance gv2 status Node Rebalanced-files size scanned failures skipped status run time in h:m:s --------- ----------- ----------- ----------- ----------- ----------- ------------ -------------- localhost 0 0Bytes 11 0 6 completed 0:0:1 mystorage4 0 0Bytes 0 0 0 completed 0:0:1 mystorage2 0 0Bytes 0 0 0 completed 0:0:1 mystorage3 0 0Bytes 0 0 0 completed 0:0:0 volume rebalance: gv2: success
移除brick
注意:你可能想在线缩小卷的大小,
例如:当硬件损坏或者网络故障的时候,你可能想在卷中移除相关的bricks。
注意:当你移除bricks的时候,你在 gluster的挂载点将不能继续访问数据,只有配置文件中的信息移除后你才能继续访问bricks的数据。当移除分布式复制卷或者分布式条带卷的时候, 移除的bricks数目必须是replica或者stripe的倍数。
例如:一个分布式条带卷的stripe是2,当你移除bricks的时候必须是2、 4、6、8等。
#执行命令
[root@mystorage1 brick2]# gluster volume stop gv2 Stopping volume will make its data inaccessible. Do you want to continue? (y/n) y volume stop: gv2: success [root@mystorage1 brick2]# gluster volume remove-brick gv2 replica 2 mystorage3:/storage/brick2 mystorage4:/storage/brick2 force Removing brick(s) can result in data loss. Do you want to Continue? (y/n) y volume remove-brick commit force: success
删除卷
[root@mystorage1 brick2]# umount /gv1 [root@mystorage1 brick2]# gluster volume stop gv1 Stopping volume will make its data inaccessible. Do you want to continue? (y/n) y volume stop: gv1: success [root@mystorage1 brick2]# gluster volume delete gv1 Deleting volume will erase all information about the volume. Do you want to continue? (y/n) y volume delete: gv1: success [root@mystorage1 brick2]# gluster volume info gv1 Volume gv1 does not exist
三、构建企业级分布式存储
3.1 硬件要求
一般选择2U的机型,磁盘STAT盘4T,如果I/O 要求比较高,可以采购SSD固态硬盘。
为了充分保证系统的稳定性和性能,要求所有glusterfs服务器硬件配置尽量一致,尤其是硬盘数量和大小。机器的RAID卡需要带电池,缓存越大,性能越好。一般情况下,建议做RAID10,如果出于空间要求的考虑,需要做RAID5,建议最好能有1-2块硬盘的热备盘。
3.2 系统要求和分区划分
系统要求使用centos 6.x,安装完成后升级到最新版本,安装的时候,不要使用LV,建议/boot分区200M,/ 分区100G、swap分区和内存一样大小,剩余空间给gluster使用,划分单独的硬盘空间。系统安装软件没有特殊要求,建议除了开发工具和基本的管理软件,其他软件一律不安装。
3.3 网络环境
网络要求全部千兆环境,gluster服务器至少有2块网卡,1块网卡绑定供gluster使用,剩余一块分配管理网络ip,用于系统管理。如果有条件购买万兆交换机,服务器配置万兆网卡,存储性能性能会更好。网络方面如果安全性要求较高,可以多网卡绑定。
3.4 服务器摆放分布
服务器主备机器要放在不同的机柜, 连接不同的交换机,及时一个机构出现问题,还有一份数据正常访问。
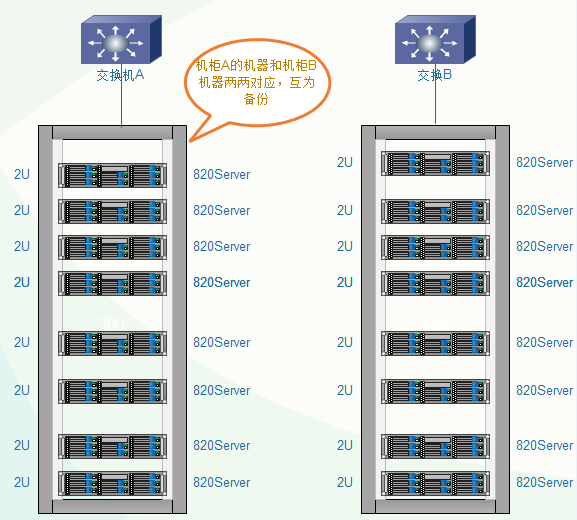
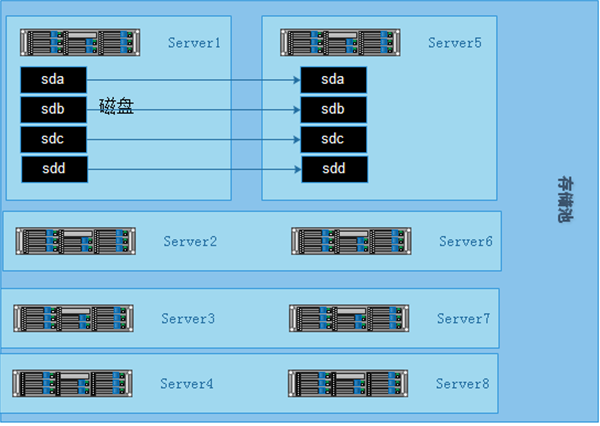
3.5 构建高可用、高性能存储
一般在企业中,采用的是分布式复制卷,因为有数据备份,数据相对安全,分布式条带卷目前对glusterfs 来说没有完全成熟,存在一定的数据安全风险
3.5.1 开放防火墙端口
一般在企业应用中Linux防火墙是打开,这些开通服务器之间访问的端口
iptables -I INPUT -p tcp --dport 24007:24011 -j ACCEPT iptables -I INPUT -p tcp --dport 38465:38485 -j ACCEPT
3.5.2 文件系统优化
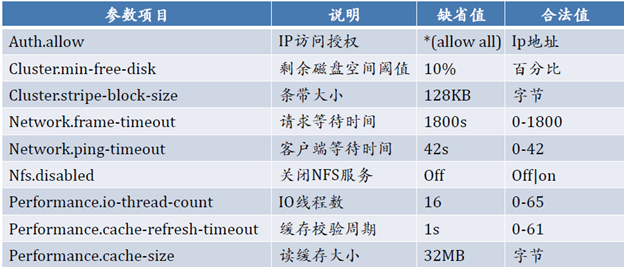
Performance.quick-read:优化读取小文件的性能。
Performance.read-ahead:用预读的方式提高读取的性能,有利于应用频繁持续性的访问文件,当应用完成当前数据块读取的时候,下一个数据块就已经准备好了。
Performance.write-behind:在写数据时,先写入缓存内,再写入硬盘,以提高写入的性能。
Performance.io-cache:缓存已经被读过的
#调整方法
Glustervolume set <卷> <参数>
演示:
[root@mystorage1 ~]# gluster volume set gv2 performance.read-ahead on volume set: success [root@mystorage1 ~]# gluster volume set gv2 performance.cache-size 256MB volume set: success [root@mystorage1 ~]# gluster volume info gv2 Volume Name: gv2 Type: Replicate Volume ID: ee6aee88-a837-43dd-9335-148e09086248 Status: Stopped Number of Bricks: 1 x 2 = 2 Transport-type: tcp Bricks: Brick1: mystorage1:/storage/brick2 Brick2: mystorage2:/storage/brick2 Options Reconfigured: performance.cache-size: 256MB performance.read-ahead: on performance.readdir-ahead: on
3.6 监控及日常维护
使用zabbix自带模板即可。Cpu、内存、主机存活、磁盘空间、主机运行时间、系统load。日常情况要查看服务器的监控值,遇到报警要及时处理。
# gluster volume status gv1(看看这个节点有没有在线)
# gluster volume heal gv2 full (启动完全修复)
# gluster volume heal gv2 info (查看需要修复的文件)
# gluster volume heal gv2 info healed (查看修复成功的文件)
# gluster volume heal gv2 info heal-failed (查看修复失败的文件)
# gluster volume heal gv2 info split-brain (查看脑裂的文件)
# gluster volume quota gv2 enable -- 激活 quota 功能
# gluster volume quota gv2 disable -- 关闭 quota 功能
# gluster volume quota gv2 limit-usage /data 10GB --/gv2/data 目录限制
# gluster volume quota gv2 list --quota 信息列表
# gluster volume quota gv2 list /data -- 限制目录的 quota 信息
# gluster volume set gv2 features.quota-timeout 5 -- 设置信息的超时时间
# gluster volume quota gv2 remove /data –删除某个目录的 quota 设置
备注: quota 功能,主要是对挂载点下的某个目录进行空间限额。 如 :/mnt/glusterfs/data 目录 . 而不是对组成卷组的空间进行限制
四、生产故障及解决
4.1 硬盘故障
因为底层做了raid配置,有硬件故障,直接更换硬盘,会自动同步数据。
如果没有做raid的处理方法:
正常node执行gluster peer status 记录故障节点uuid
执行getfattr -d -m '.*' /storage/brick1/
记录 trusted.glusterfs.volume-id及trusted.gfid
例如:
[root@mystorage1 ~]# getfattr -d -m '.*' /storage/brick1/ getfattr: Removing leading '/' from absolute path names # file: storage/brick1/ trusted.gfid=0sAAAAAAAAAAAAAAAAAAAAAQ== trusted.glusterfs.dht=0sAAAAAQAAAAAAAAAAf////g== trusted.glusterfs.volume-id=0sxNSl8h7UTd+jFJ3L+2eJSw==
在机器上更换新磁盘,挂载目录
执行如下命令:
setfattr -n trusted.glusterfs.volume-id -v 记录值 brickpath
setfattr -n trusted.gfid -v 记录值 brickpath
service glusterd restart
4.2 一台主机故障
一台节点故障的情况包括以下情况:
a) 物理故障;
b) 同时有多块硬盘故障,造成数据丢失;
c) 系统损坏不可修复。
解决方法:
找一台完全一样的机器,至少要保证硬盘数量和大小一致,安装系统,配置和故障机同样的ip,安装gluster软件,保证配置都一样,在其他健康的节点上执行命令gluster peer status,查看故障服务器的uuid,
[root@mystorage1 ~]# gluster peer status Number of Peers: 3 Hostname: mystorage4 Uuid: d145a3f4-47bc-4c24-ac21-dbe1e2befd29 State: Peer in Cluster (Connected) Hostname: mystorage2 Uuid: 84f9d2ba-8dc8-4c56-a6a1-7c17db413ea2 State: Peer in Cluster (Connected) Hostname: mystorage3 Uuid: 8f95f447-a786-4463-9fe4-2c92c0ff8c81 State: Peer in Cluster (Connected)
修改新加机器的/var/lib/glusterd/glusterd.info和故障机器的一样
cat /var/lib/glusterd/glusterd.info
UUID= 2e3b51aa-45b2-4cc0-bc44-457d42210ff1
在新机器 挂载目录上执行磁盘故障的操作
在任意节点上执行
root@drbd01 ~]# gluster volume heal gv1 full
Launching Heal operation on volume gv2 has been successful
就会自动开始同步,但是同步的时候会影响整个系统的性能。
可以查看状态
[root@drbd01 ~]# gluster volume heal gv2 info
Gathering Heal info on volume gv2 has been successful
神回复
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。